
原文:A Brief History of Microprogramming
原文作者:Mark Smotherman
Last updated: October 2024
摘要 微程序设计是一种在处理器内实现执行指令所需控制逻辑的技术。它基于从控制存储器中提取低级微指令,并从每条微指令中推导出在单个时钟周期内应激活的适当控制信号以及微程序序列信息的一般思想。尽管混合技术现在很常见,但微程序设计通常与硬连线实现技术形成对比。
定义和实例
尽管有时不严谨地使用术语“微程序设计”来等同于“对微型计算机进行编程”的概念,但这并不是标准的定义。相反,微程序设计是一种系统化的技术,用于实现计算机中央处理单元(CPU)的控制逻辑。它是存储程序逻辑的一种形式,替代了硬连线控制电路。
计算机系统中的中央处理单元由数据通路(data path)和控制单元(control unit)组成。数据通路包括寄存器、功能单元(如移位器和算术逻辑单元(ALU))、内部处理器总线和路径,以及用于主存储器和I/O总线的接口单元。控制单元管理数据通路在执行用户可见指令(或宏指令(macroinstruction),例如加载、加法、存储)期间所采取的一系列步骤。
数据通路的每个动作称为寄存器传输(register transfer),涉及数据通路内部信息的传输,可能包括通过功能单元对数据、地址或指令位的转换。寄存器传输通过将寄存器内容门控输出(发送)到内部处理器总线上,选择ALU、移位器等操作,并通过这些操作传递信息,以及门控输入(接收)一个或多个寄存器的新值来实现。
控制寄存器发送或接收数据的寄存器使能信号,以及控制功能单元动作的操作选择信号,称为控制信号(control signals)。这些信号由控制单元提供。数据通路中响应使能信号并允许在寄存器发送或接收数据的逻辑门集合称为控制点(control points)。
因此,宏指令执行的每一步都由一个或多个寄存器传输组成,而完整的宏指令通过生成一组适时且适当的控制信号序列来执行。单个数据通路动作或相关动作集合通常称为微操作(microoperations)。
例如,考虑图1中的简单处理单元。该数据通路支持基于累加器的四条宏指令(加载、加法、存储和条件分支)。累加器(ACC)和程序计数器(PC)对宏指令级程序员可见,但其他寄存器则不可见。
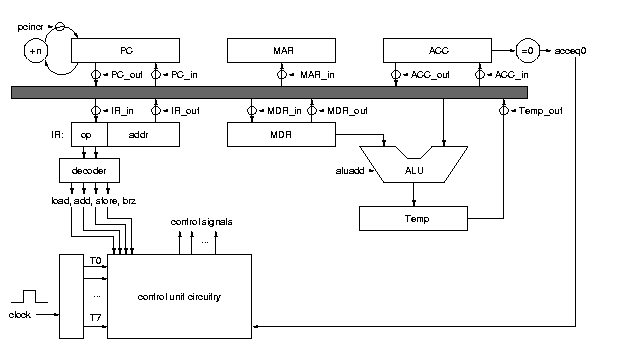
图1 一个支持4条指令的计算机的简单数据通路(小圆圈的含义是控制点)
图2给出了四条宏指令的定义,图3给出了用于该数据通路的控制信号的定义。在这个数据通路中,控制信号如ACC_in和ACC_out是寄存器使能信号,而控制信号如aluadd和pcincr是操作选择信号。
(opcode 00) load address : ACC <- memory[ address ]
(opcode 01) add address : ACC <- ACC + memory[ address ]
(opcode 10) store address : memory[ address ] <- ACC
(opcode 11) brz address : if( ACC == 0 ) PC <- address图2 该计算机的指令定义
ACC_in : ACC <- CPU internal bus
ACC_out : CPU internal bus <- ACC
aluadd : addition is selected as the ALU operation
IR_in : IR <- CPU internal bus
IR_out : CPU internal bus <- address portion of IR
MAR_in : MAR <- CPU internal bus
MDR_in : MDR <- CPU internal bus
MDR_out : CPU internal bus <- MDR
PC_in : PC <- CPU internal bus
PC_out : CPU internal bus <- PC
pcincr : PC <- PC + 1
read : MDR <- memory[ MAR ]
TEMP_out : CPU internal bus <- TEMP
write : memory[ MAR ] <- MDR图3 简单数据通路控制信号定义
为了在这个数据通路上实现宏指令的处理,首先需要一组控制信号从内存中获取宏指令。这些控制信号将程序计数器的内容门控到内部总线上,并将这些位从内部总线门控到内存地址寄存器中。无论是在这组控制信号中(即在第一个时间步)还是在下一个时间步,程序计数器都应该递增,并且内存接口应该发送一个信号以触发内存读取。在内存读取完成后(这可能是一个同步或异步事件),内存数据寄存器的内容被传输到指令寄存器。
一旦宏指令的位进入指令寄存器,操作码字段中的位就可以用来控制剩余的步骤。这些步骤包括获取任何操作数、执行操作码指定的功能以及存储任何结果。在这个数据通路上,简单宏指令的完整处理可能需要五到十个时间步,并且可能涉及十几个或更多的控制信号。
图4给出了四条宏指令的控制序列。对于这个简单的例子,假设内存读取或写入在一个时间步内完成。(通常,一个时间步可能对应一个时钟周期,但处理器可以延长任何需要访问内存的时间步,以提供足够的时间来完成内存访问。)
time steps T0-T3 for each instruction fetch:
T0: PC_out, MAR_in
T1: read, pcincr
T2: MDR_out, IR_in
T3: time step (if needed) for decoding the opcode in the IR
time steps T4-T6 for the load instruction:
T4: IR_out(addr part), MAR_in
T5: read
T6: MDR_out, ACC_in, reset to T0
time steps T4-T7 for the add instruction:
T4: IR_out(addr part), MAR_in
T5: read
T6: ACC_out, aluadd
T7: TEMP_out, ACC_in, reset to T0
time steps T4-T6 for the store instruction:
T4: IR_out(addr part), MAR_in
T5: ACC_out, MDR_in
T6: write, reset to T0
time steps T4-T5 for the brz (branch on zero) instruction:
T4: if (acceq0) then { IR_out(addr part), PC_in }
T5: reset to T0图4 4条指令的控制序列
如上所述,控制单元负责生成控制信号的序列。如图1左下角所示,控制单元的输入包括:
一组互斥的时间步信号,
一组互斥的解码操作码信号,以及
用于实现条件分支指令的条件信号。
单个控制信号的逻辑表达式可以写成乘积和的形式,其中项通常由给定的时间步信号与识别特定指令操作码的操作码信号相与组成。然而,给定的项也可能仅由时间步信号组成,或者它可能包含一个或多个条件信号。控制信号将在指令获取和执行期间的一个或多个特定时间步中被断言。
简单示例的控制信号的逻辑表达式如图5所示。例如,ACC_in的逻辑表达式具有典型形式,并在时间步T6时对加载指令和在时间步T7时对加法指令评估为真。IR_in有一个简单的表达式,并在时间步T2时对所有指令评估为真。PC_in在时间步T4时对brz指令条件为真,因为条件信号acceq0作为项的一部分被包含在内。
ACC_in = (load & T6) + (add & T7)
ACC_out = (store & T5) + (add & T6)
aluadd = add & T6
IR_in = T2
IR_out(addr part) = (load & T4) + (add & T4) + (store & T4) + (brz & acceq0 & T4)
MAR_in = T0 + (load & T4) + (add & T4) + (store & T4)
MDR_in = store & T5
MDR_out = T2 + (load & T6)
PC_in = brz & acceq0 & T4
PC_out = T0
pcincr = T1
read = T1 + (load & T5) + (add & T5)
TEMP_out = add & T7
write = store & T6图5 控制信号的乘积和定义
当控制信号的逻辑表达式直接用单个逻辑门或不完全解码的门阵列(如可编程逻辑阵列(PLA))实现时,控制单元被称为硬连线。图6描绘了用逻辑门直接实现的示意图。直接实现中逻辑门的典型不规则布局导致这种方法被称为“随机逻辑”。(另请参阅下面关于MIT Whirlwind和其他早期硬连线控制设计中的控制设计的附录部分。)
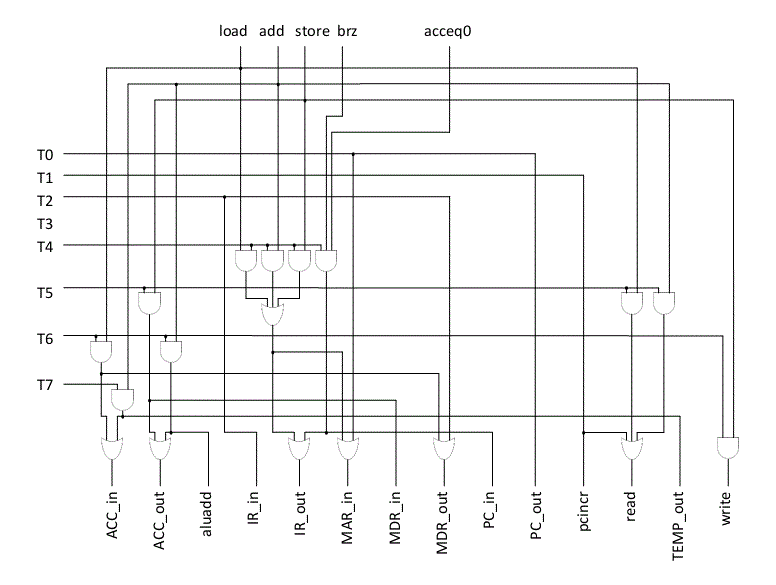
图6 对于该计算机4条指令的硬连线实现
另外,在微程序控制单元中,在给定时间步生成的控制信号被存储在一起,形成一个控制字,称为微指令(microinstruction)。实现一条指令的控制字的集合称为微程序(microprogram),微程序存储在一个称为控制存储器(control store)的存储元件中。
简单示例的微程序控制实现如图7所示。控制存储器是一个16 x 20位的存储器。它由控制存储器地址寄存器(CSAR)访问,取出的字保存在控制存储器指令寄存器(CSIR)中。因此,给定时间步所需的控制信号通过CSIR提供给数据通路。
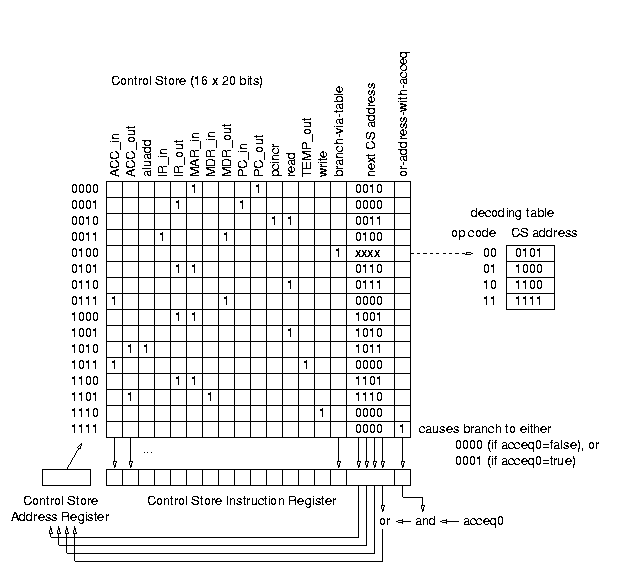
图7 控制存储器(控制比特为0的未显示)
图7中的每条微指令的前十四个位是用于图1数据通路的寄存器使能和操作选择控制信号。图7中的每条微指令还使用了六个额外的位来实现顺序控制。
这六个位包括一个四位的下一地址字段和一个一位的覆盖信号(通过表分支),该信号导致从单独的解码表中加载下一地址,而不是使用下一地址字段。在这个例子中,解码表由指令寄存器中的两位操作码字段索引,并提供与该特定操作码相关联的微程序在控制存储器中的入口点地址。
第六位(或地址与acceq)用于通过允许条件信号acceq0有条件地改变下一地址字段中的最低有效位来处理条件分支。当微指令中的下一地址字段以0结尾时,会发生这种情况,因此将从以0结尾的地址或顺序跟随的以1结尾的地址中获取下一条微指令,具体取决于条件信号分别为假或真。
图8展示了从图7的控制存储器中获取四条指令的顺序。
clock CSAR control signals
cycle
0 0000 PC_out, MAR_in
1 0010 read, pcincr
2 0011 MDR_out, IR_in
3 0100 branch-via-table (to one of the cases below)
a load instruction causes a branch to 0101 for cycle 4:
4 0101 IR_out(addr part), MAR_in
5 0110 read
6 0111 MDR_out, ACC_in (and jump to 0000)
or an add instruction causes a branch to 1000 for cycle 4:
4 1000 IR_out(addr part), MAR_in
5 1001 read
6 1010 ACC_out, aluadd
7 1011 TEMP_out, ACC_in (and jump to 0000)
or a store instruction causes a branch to 1100 for cycle 4:
4 1100 IR_out(addr part), MAR_in
5 1101 ACC_out, MDR_in
6 1110 write (and jump to 0000)
or a brz instruction causes a branch to 1111 for cycle 4; the branch
may either be untaken, in which case control returns to the start
of the next macroinstruction fetch at address 0000:
4 1111 or_address_with_acceq0 (yields jump to 0000)
or it may be a taken branch, in which case the true condition bit
modifies the next-address field and directs the control store
fetch for cycle 5 to a microinstruction that changes the PC:
4 1111 or_address_with_acceq0 (yields jump to 0001)
5 0001 IR_out(addr part), PC_in (and jump to 0000)图8 控制存储器取数序列
如本例所示,在微程序控制单元中,指令获取和执行所需的控制信号序列来自于从控制存储器中一系列的获取,而不是硬连线电路的操作。其结果是,控制设计更加系统化,允许通过改变控制存储器的内容来实现更改,而不是重新布线或重新合成硬连线电路。
需要注意的是,上述控制存储器使用完全未编码的控制信号存储方式。这种方式效率低下(注意所有的零位置),实际实现中会将控制信号分组编码。例如,所有用于将寄存器内容门控到单个共享总线上的信号是互斥的,可以编码到一个字段中。实际上,商用处理器中的典型微指令由一组不同大小的编码字段组成,而不是包含单个控制信号的位向量。
由于微指令和微程序介于逻辑设计(硬件)和正在执行的宏指令程序(软件)之间,它们有时被称为固件(firmware)。这个术语的使用也比较宽松。Ascher Opler在1967年的一篇Datamation文章中首次定义了它,作为可写控制存储器(writable control store)的内容,可以根据需要重新加载,以使计算机的用户界面专门化于特定的编程语言或应用程序[Opl67]。然而,在后来的普遍使用中,该术语逐渐指代任何类型的微码,无论其驻留在只读还是可写控制存储器中。最近,该术语的范围扩大到表示任何ROM驻留的内容,包括BIOS、引导加载程序或专用应用程序的宏指令级例程。
有关数据通路设计、控制信号、硬连线和微程序的概述,请参阅Hamacher、Vranesic和Zaky[Ham90]的第4章和第5章,以及Patterson和Hennessy[Pat98]的第5章。专门讨论微程序设计问题的旧文本包括Agrawala和Rauscher[Agr76]、Andrews[And80]、Habib[Hab88]和Husson[Hus70]。ACM和IEEE赞助了二十多年的年度微程序设计研讨会,并出版了会议论文集;1991年,研讨会更名为国际微架构研讨会,以反映重点转向更广泛的微架构(microarchitecture)领域,即处理器的内部设计,包括分支预测、多指令执行和低功耗设计等领域。
微编程的历史
在20世纪40年代末,剑桥大学的Maurice Wilkes开始致力于名为EDSAC(电子延迟存储自动计算器)的存储程序计算机的工作。在此期间,Wilkes访问了麻省理工学院的旋风计算机,并观察了旋风计算机的二极管矩阵“控制存储器”[Wil85]。(参见下面的旋风附录部分。)Wilkes认识到,计算机内部控制信号的顺序类似于常规程序中所需的顺序操作,并且他可以使用存储程序来表示控制信号的序列[Wil85]。1951年,他发表了关于这项技术的首篇论文,他称之为微程序设计[Wil51]。
在Wilkes的开创性论文中,他描述了使用二极管矩阵实现控制存储器的方法。控制存储器中的微指令具有类似于上述例子的简单格式:未编码的控制信号与下一地址字段一起存储。初始选择适当的微程序是通过将操作码值附加零作为控制存储器中的起始地址来处理的,之后的正常顺序使用下一地址字段的内容。条件转移通过允许条件选择多个可能的下一地址字段之一来处理。
在1953年发表的一篇扩展论文中,Wilkes和他的同事John Stringer进一步描述了这项技术[Wil53]。图9再现了1953年论文中的一个图表。在这篇具有远见的论文中,他们还考虑了设计复杂性、控制逻辑的测试和验证、控制逻辑的交替和后续添加、支持不同的宏指令集(通过使用不同的矩阵)、利用数据通路内的并行性、多路分支、环境替换、微子程序、可变长度和多相定时以及控制存储器的流水线访问等问题。
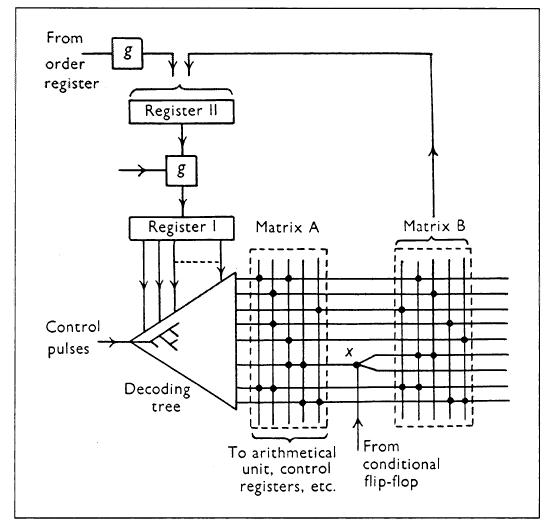
图9 威尔克斯的微编程设计
剑桥大学的团队,包括William Renwick和David Wheeler,在1957年实现了并测试了第一台微程序计算机。由于二极管矩阵对于具有完整指令集的计算机来说太大,他们使用了磁芯矩阵[Whe92]。在矩阵的每个交叉点,磁芯可以通过同时电流切换,然后用于驱动多个控制信号以及顺序信号。矩阵还可以在交叉点处连接两个或四个磁芯,以实现条件控制和条件顺序;来自条件触发器的导线会以这样的方式缠绕在这些磁芯上,即一次只能切换一个磁芯[Ren56,Wil92]。
在1957年的初步测试中,他们使用了一个8×6的磁芯矩阵,Wheeler将这种安排描述为具有“64个微程序步骤”[Whe92]。这台机器被称为EDSAC 1½。完整的EDSAC 2于1958年投入运行,并使用了一个32×32的磁芯矩阵。Wheeler将EDSAC 2描述为具有“1024个步骤的微程序,包括一个完整的128步指令解码器,因此未列出的指令会产生‘报告停止’”[Whe92]。EDSAC 2还使用了位切片设计方法用于ALU和索引寄存器,以帮助系统化算术电路的设计并使维护更容易。
由于20世纪50年代制造快速控制存储器的困难,微程序设计并未立即成为主流技术。然而,一些计算机项目确实追求了Wilkes的想法。例如,德国的Heinz Billing和Wilhelm Hopmann设计了使用磁致伸缩延迟线的哥廷根G1a的微程序控制[Hop00];这项工作反过来影响了Zuse Z22和Telefunken TR-4的控制设计。在英国,EMIDEC 1100和LEO III是早期基于微程序设计的晶体管计算机的例子。
在英国IBM的Hursley实验室,John Fairclough在20世纪50年代末也领导了一项开发工作,探索了用于小型计算机控制单元的只读磁芯矩阵。这项工作导致了SCAMP(科学计算机和调制处理器)的诞生。1961年,Fairclough的经验在IBM决定追求一系列兼容计算机方面发挥了关键作用,这些计算机于1964年作为System/360宣布[Pug91]。最初的360型号中,除了高端的Model 75和91之外,其他所有型号都是微程序设计的[Tuc67]。
因此,微程序设计成为例如低成本、字节宽的Model 30实现能够实现完整的32位System/360指令集架构的手段。表1比较了最初微程序设计的360型号。
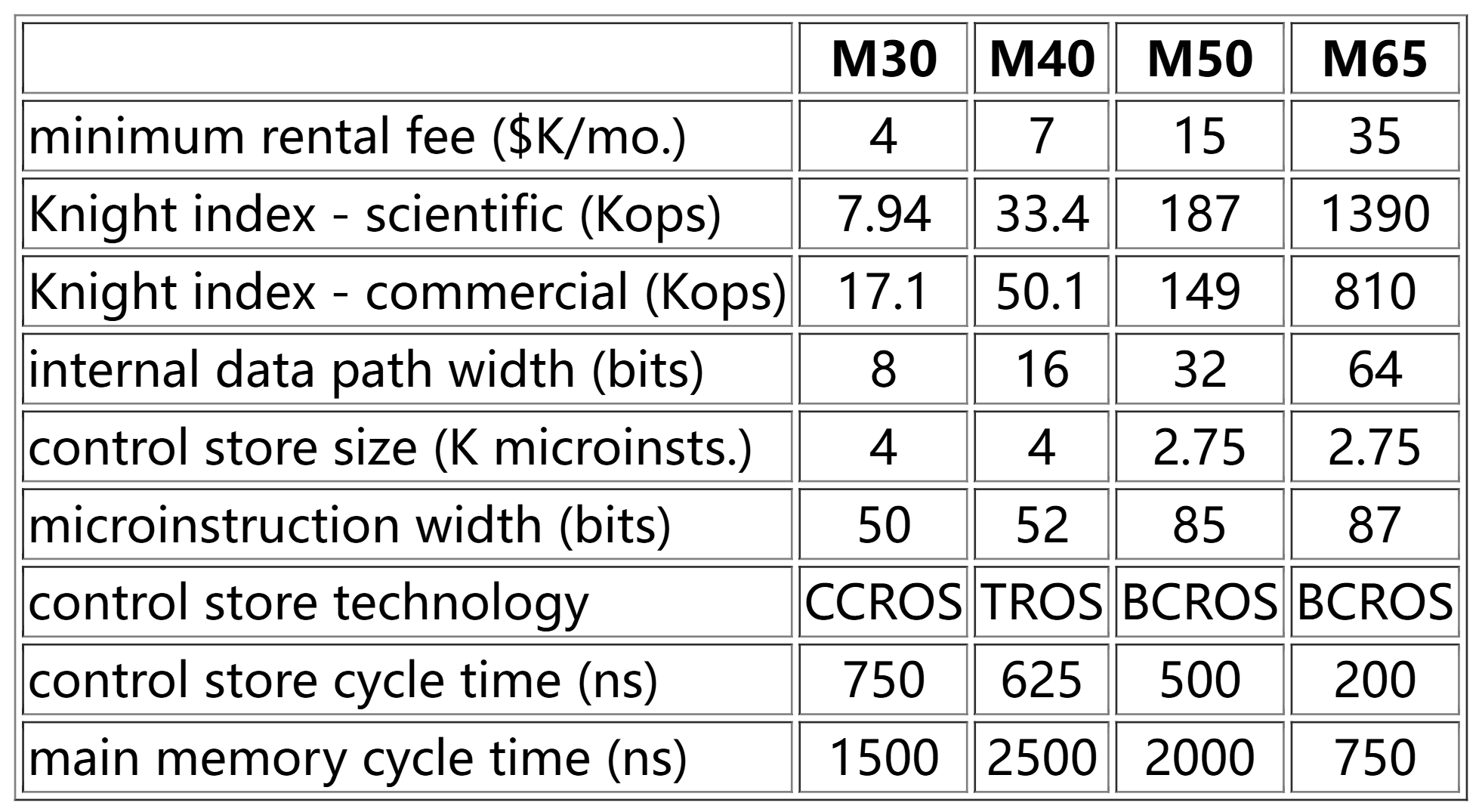
图9 IBM System/360 30-65型号对比
由于微程序设计对于兼容性计划至关重要,IBM积极追求三种不同类型的只读控制存储技术[Pug91]。首先是平衡电容只读存储器(BCROS),它每比特位使用两个电容器,存储容量为2816个字,每个字100位。第二种技术是变压器只读存储器(TROS),它采用了Fairclough在Hursley使用的磁芯方法,存储容量为8192个字,每个字54位。
第三种技术是为Model 30开发的卡片电容只读存储器(CCROS)。该技术基于标准穿孔卡片大小的聚酯卡片,卡片上封装了铜片和访问线路。可以使用标准卡片穿孔机从卡片的12乘60位区域中移除一些铜片。移除的铜片通过感应线路读取为零,而剩余的铜片读取为1。在Model 30的机柜中安装了由42块板组成的组件,每块板上有8张卡片。
Model 30上的CCROS卡片可以在现场更换。这使得设计修改更容易实现,同时也为现场诊断提供了便利。Model 30的控制存储器分为两部分:一部分用于驻留例程,另一部分由六张CCROS卡片组成,用于存放特定测试例程[Joh71]。工程师在运行机器诊断时,可以用几组CCROS卡片中的一组来“填充”保留的板卡。
后来的System/360 Model 25和System/370系列的部分型号配置了至少一部分可读写的控制存储器,用于加载微码补丁和微诊断程序。(在较小的System/370型号上,控制存储器的一部分分配在主存中)。实际上,IBM发明了8英寸软盘及其驱动器,以改进微码补丁和诊断程序的分发[Pug91];1971年,软盘用于在2835和3830磁盘存储控制单元以及System/370 Model 145上加载微码和诊断程序[Ste81]。145型号具有可写控制存储器(WCS),容量高达16K字,每字32位。
在20世纪60年代中期,IBM产品线向新的System/360过渡期间,大型客户在遗留软件上的投资,特别是在汇编语言级别上的投资,并未得到充分认识[Tuc99]。计划通过重新编译高级语言程序来进行软件转换,但由于依赖机器的代码广泛使用以及客户(和经济上的不可行性)不愿意转换所有这些依赖机器的代码,因此需要提供旧计算机的模拟器。然而,对模拟器的初步研究表明,性能最多会下降十倍到两倍[Pug91]。与此同时,竞争对手正试图通过提供更兼容的硬件和自动转换工具(如Honeywell的“解放者”程序,该程序接受IBM 1401程序并将其转换为类似1401的Honeywell H-200程序)来吸引IBM客户,这些工具的转换工作量较小。
当System/360 Model 30的工程师建议使用一个可以通过手动开关选择的额外控制存储器,使Model 30能够执行IBM 1401指令时,IBM避免了大量前客户的流失[McC65]。随后,模拟器和控制存储器的想法被结合在一起,研究将模拟器程序的关键部分作为微程序编入控制存储器。Stuart Tucker和Larry Moss领导了开发硬件、软件和微程序组合的工作,以执行不仅适用于IBM 1401计算机,还适用于IBM 7000系列的遗留软件[Tuc65]。Moss认为他们的工作不仅仅是模仿,而且在性能上等于或超过了原始版本;因此,他将他们的工作称为仿真[Pug91]。他们设计的仿真器工作得足够好,以至于许多客户从未转换遗留软件,而是在System/360硬件上使用仿真运行了多年。
由于IBM System/360产品线的成功,到20世纪60年代末,微程序设计成为大多数计算机(除了最快和最简单的计算机)的首选实现技术。这种情况持续了大约二十年。例如,除了Model 195之外的所有IBM System/370型号,以及除了PDP-11/20之外的所有DEC PDP-11型号,都是通过微程序设计的。
在微程序设计可能达到其流行顶峰的时候,1978年交付的DEC VAX 11/780配备了一个4K字的只读控制存储器,每字96位,以及一个额外的1K可写区域,用于诊断和微码补丁。11/780的一个额外成本选项是1K的用户可写控制存储器。
一些早期的微处理器是硬连线的,但很快微程序设计就成为常见的控制单元设计特征。例如,在1974年至1976年间生产的主要八位微处理器中,MC6800是硬连线的,而Intel 8080和Zilog Z80则是微程序设计的[Anc86]。1978年16位微处理器之间的一个有趣对比是硬连线的Z8000[Shi79]和微程序设计的Intel 8086[McK79]。8086使用了一个包含504个条目的控制存储器,每个条目包含一个相当通用的21位微指令。额外的解码逻辑用于将微指令定制为特定的字节宽或字宽操作。1978年,Motorola 68000的微程序设计被描述为[Anc86, Str78, Tre88]。该设计包含一个复杂的两级方案。每个17位微指令可以包含一个10位的微指令跳转地址或一个9位的“纳米指令”地址。纳米指令是单独存储的68位字,它们标识了在给定时钟周期内要执行的微操作。额外的解码逻辑与纳米指令内容一起用于驱动196个控制信号。
Nick Tredennick在1982年的一篇文章中描述了微程序设计的四个主要用途的发展,他将这些用途称为文化[Tre82]:
商用机器(Commercial machine) - 在这种使用模式下,微程序设计用于实现标准计算机系列的指令集。用户无法访问微代码,但控制存储器设计为可写,以便制造商可以对微代码进行更改。IBM System/370系列是一个主要例子[Pad81]。商用机器还使用微程序设计来实现操作系统功能,从专用辅助功能(例如,IBM VM/370辅助功能提供了45%-65%的OS调用时间减少[Pad81])到操作系统内核的主要部分(例如,法国设计的Honeywell Series 60 Level 64,后来称为DPS-7,通过微程序设计实现了线程和信号量操作[Atk74])。
单芯片(Single-chip) - 对于微处理器,微程序设计是一种用于简化设计的实现技术。控制存储器通常是只读的,不修改用于芯片制造的掩模就无法更改。MC68000系列是一个例子[Tre88]。(然而,请注意,更新的微处理器包含小型微代码RAM,这些RAM提供了微代码更新和补丁,可以覆盖基于ROM的微代码。这类似于商用机器提供的能力,但通常更为有限。有关此功能的示例,请参见[Bad92],其中使用了一个20字的RAM来修补单芯片DEC NVAX微处理器中微序列器的1600字ROM。)
位片(Bit-slice) - 在VLSI ASIC广泛使用之前,设计师会使用商用现成的微程序序列器和数据路径构建块来构建特定应用的机器。数据路径组件是ALU加上寄存器文件的两到四位宽的切片,多个切片可以连接在一起以构建所需宽度的数据路径。有多个组件和序列器系列,包括Intel 3001/3002、AMD 2901/2909和2903/2910、TI 74S和MC10800。更多详情请参见Andrews [And80]和Mick与Brick [Mic80]。
可微程序设计的机器(Microprogrammable machine) - 由于像PDP-11/60和VAX-11/750这样的小型计算机变得可用,并且提供了相当容易的用户访问可写控制存储器,用户微程序设计变得流行起来。例如,Jim Larus发表了一项关于VAX-11/750上模式匹配的研究,报告称微程序实现的执行性能比手工编写的汇编语言或编译的C程序快14-28倍[Lar82]。1978年,Bell、Mudge和McNamara估计微程序设计的生产力为每年700微指令[Bel78]。这意味着微程序设计比相同任务的传统编程贵五到十倍,但估计微程序设计通常在性能上快十倍。
可微程序设计的机器文化中的一个重要子领域是希望生产一种通用主机机器(universal host machine),具有通用数据路径,以便高效地模拟任何宏指令集架构或各种高级语言导向的机器接口。这方面的例子包括Nanodata QM-1(约1970年)[Agr76,Nanodata,Sal76]和Burroughs B1700(约1972年)[Bar92,Burroughs,Mye78,Sal76]。QM-1上的ALU操作可以选择为18位或16位,二进制或十进制,以及无符号或补码或反码。然而,即使努力提供这样一组通用操作,主机和目标机器数据类型和寻址结构之间不可避免的错配从未允许通用主机概念无条件成功。
B1700可能是商业机器中最接近Opler原始固件愿景的机器。其内存中可以保存多组微程序,每组微程序呈现不同的高级宏指令接口。B1700操作系统是用一种称为SDL的语言编写的,而应用程序通常用Fortran、Cobol和RPG编写。因此,B1700的控制存储器可以保存SDL导向接口的微程序,以及Fortran导向接口和Cobol/RPG导向接口的微程序。在中断时,B1700会使用SDL导向的微程序执行操作系统代码,然后在进程切换时,操作系统可以切换系统到Fortran导向的微程序或Cobol/RPG导向的微程序。Baron和Higbie质疑B1700选择24位字长、缺乏补码算术支持、地址空间限制以及有限的中断和I/O设施,但他们主要将B1700有限的商业成功归因于缺乏面向开发者的操作系统文档[Bar92]。
从七十年代末开始,宏指令集的复杂性增长趋势逐渐显现。VAX-11/780超级小型计算机和MC68020微处理器是这一趋势的例子,这一趋势被称为CISC(复杂指令集计算机)。复杂性增加的趋势通常归因于当时微程序设计的成功。摆脱了先前由于实现问题带来的限制,VAX设计者强调了编译的便利性[Bel78]。例如,一个设计标准是操作数规范的通用性。然而,结果是VAX拥有复杂的、可变长度的指令,这使得高性能实现变得困难[Bha91]。
与最初的MC68000(约1979年)相比,MC68020(约1984年)增加了虚拟内存支持、未对齐数据访问、额外的堆栈指针和状态寄存器位、六个额外的堆栈帧格式、大约二十多个新指令、两种新的寻址模式(总共14种)以及18种新的寻址模式内偏移格式(总共25种)。为了支持这些功能,微代码存储从36 KB增加到85 KB[Tre88]。MC68020上的复杂内存间接寻址模式代表了由控制存储器访问时间仅为主内存访问时间一小部分所引发的设计风格。这种风格预计每个宏指令将生成大量寄存器传输,因此只需从主内存中获取相对较少的复杂宏指令来执行程序。
除了“正常”宏指令集架构内复杂性增长的趋势外,还有一个强烈的呼吁要“弥合语义鸿沟”,假设更高级别的机器接口将简化软件构建和编译。有关这一论点的概述,请参见Myers [Mye78]的第1章。
然而,从20世纪80年代开始,人们对复杂性增长的趋势产生了反应。几个技术发展推动了这一反应。一个发展是VLSI技术使得片上或近片高速缓存内存变得有吸引力和成本效益;实际上,MC68030(约1987年)包含了双256字节指令和数据高速缓存,而MC68040(约1989年)则包含了双4K字节指令和数据高速缓存。因此,有效内存访问时间现在更接近处理器时钟周期时间。
第二个发展是广泛使用VLSI设计工具和设计师能够轻松使用这些CAD工具合成硬连线设计的能力。控制单元设计的更改成为通过模拟和合成工具链运行更改设计的问题,几乎不需要电路设计师进行控制逻辑的定制设计。
逻辑/内存技术比率的变化和实现硬连线控制单元的便利性为设计风格向RISC(精简指令集计算机)的转变奠定了基础,RISC的名称是为了与CISC设计形成鲜明对比。RISC设计理念主张简化指令集,以便于硬连线、高性能和流水线实现。事实上,可以将RISC指令集视为高度编码的微指令,而伴随的指令高速缓存则作为可写控制存储器的替代品。因此,RISC可以被视为直接编译为微代码,而不是使用一组固定的微程序来解释更高级别的指令集。一些RISC支持者提出的反对这一观点的论点是,RISC与向编译器暴露微程序级别的关系不大,而更多地与(1)重新发现Seymour Cray在20世纪60年代中期CDC 6600设计中展示的超级计算机设计风格,以及(2)与John Cocke在20世纪80年代初IBM 801设计中展示的硬件/软件权衡达成一致。
事实上,20世纪80年代证明了传统微程序设计使用的转折点。20世纪80年代引入的RISC微处理器,如SPARC和MIPS,都是硬连线的。在20世纪90年代,MC68000宏指令集被缩小,以便剩余的核心宏指令集可以硬连线实现[Cir95]。硬件的特定应用定制也成为一个ASIC或FPGA设计问题,而不是被视为需要定制微程序设计。
然而,微代码仍然在众多英特尔x86兼容微处理器中使用。然而,在这些设计中,简单的宏指令有一个或多个由解码器立即生成的控制字段序列组(通常称为uops或Rops),而无需从控制存储器中获取。这足以满足除最复杂宏指令之外的所有需求,最复杂的宏指令需要从片上控制存储器中由微代码序列器获取的微指令流(参见下面的微程序序列部分)。请注意,大多数x86兼容微处理器包含少量微代码RAM,用于修补微代码,称为“微代码更新”或“BIOS更新”(因为BIOS在每次开机时加载更新)。英特尔提供了一个处理器更新实用程序,可以修补P6和奔腾4微处理器的微代码。其他微处理器也有类似的方法。
IBM大型机设计也受到了从微程序控制流行回归硬连线的影响。自20世纪90年代中期以来,IBM System/390和zSeries大型机已经将许多宏指令硬连线实现[Web97]。IBM z10在硬件中实现了大约四分之三的宏指令[Web08]。剩余的复杂宏指令由一种称为“millicode”的内部代码实现,该代码使用硬件特定的milli指令,指令格式类似于宏指令[Hel05,Rog12]。
20世纪80年代的Amdahl 580大型机设计采用了类似的方法,但称其内部代码为“macrocode”[Dor88](不要与本讨论中使用的术语宏指令混淆)。同样在20世纪80年代,DEC在PRISM架构中使用了epicode,即“扩展处理器指令代码”,后来在Alpha架构中使用了PALcode,即“特权架构库代码”。
这些方法让人想起20世纪50年代EDSAC 2中的保留存储器[Wil92]和20世纪60年代初曼彻斯特Atlas中的extracodes[Lav78]。EDSAC 2中的保留存储器是额外的768个只读字和64个可写字的核心内存;这个区域受到用户访问的保护,并保存了常见的子程序,例如I/O子程序。Atlas上的extracodes以类似的方式操作,但还具有访问单独的程序计数器和保留的一组索引寄存器的能力。
与微程序设计相关的最新趋势
微程序设计或类似微程序设计的方法最近出现在与特定应用处理器、硬件/软件协同设计、代码压缩、低功耗设计和安全扩展相关的提案中。一些例子包括:
Tensilica指令扩展语言允许用户在Verilog的一个子集中定义特定应用指令和用户状态寄存器[Gon00]。这种方法可以与20世纪70年代和80年代的用户可微程序化机器相比较。然后,Tensilica设计流程在硅中实现扩展处理器。
NISC(无指令集计算机)是一种将C程序编译为微代码的方法[Res05]。
PRISA(后制造可重构ISA)提供了一个通用数据通路以及一个大型控制存储ROM,用户可以从中动态选择一个包含十五条16位指令的应用指令集,由可编程指令解码器进行解码[Che08]。可编程指令解码器本质上是一个小型WCS,可以包含较大控制存储器线路的子集副本。
斯坦福大学的ELM项目用控制和索引内存(CIM)和指令寄存器文件(IRF)取代了传统的指令缓存[Bla08]。CIM/IRF的安排类似于两级控制存储器。
代尔夫特理工大学量子与计算机工程系的科研团队定义了一种用于量子计算的微架构[Fu18]。
加州大学圣地亚哥分校的Dean Tullsen及其学生研究了“上下文敏感”的指令解码,该解码根据识别恶意软件攻击或基于电源管理需求选择不同的微代码序列,例如[Tar19]。
英特尔定义了XuCode作为一种实现复杂指令的技术,用于软件保护扩展(SGX)[Int21]。隐藏的XuCode指令集通过微代码实现。
微程序设计的不同形式
微程序的抽象级别可以根据控制信号编码的数量和微指令格式中显式并行性的数量而变化。在一端,垂直(vertical)微指令高度编码,可能看起来像一个简单的宏指令,包含一个操作码字段和一个或两个操作数说明符。例如,参见图10,该图展示了一个Microdata机器的垂直微代码示例[Microdata]。
; multiply two numbers
LF 5,X'08' ; set loop counter to 8
MT 2 ; move X to T
LF 4,X'00' ; clear ZU
ADD: TZ 3,X'01' ; if Y bit 0 set to 1
A 4,T ; add X to Z
H 4,R ; shift Z upper
H 3,L,R ; shift Z lower
D 5,C ; decrement loop counter
TN 0,X'04' ; if loop counter equal 0
JP ADD ; jump to top of loop图10 垂直微指令:微数据示例
每个垂直微指令指定一个数据路径操作,并且在解码时激活多个控制信号。垂直微程序中的分支通常作为单独的微指令处理,使用“分支”或“跳转”操作码。这种微程序设计风格对于有经验的常规汇编语言程序员来说是最自然的,类似于在RISC指令集中的编程。
在另一端,水平微指令可能是完全未编码的,每个控制信号在微指令格式中分配到一个单独的位位置(如Wilkes的原始提议和上述定义部分给出的简单示例)。然而,这种极端通常是不切实际的,因为控制信号组是互斥的,导致表示效率过低。相反,水平微指令通常使用几个控制字段,每个字段编码几个互斥选择中的一个。例如,System/360 Model 50在每个85位的微指令中使用了25个单独的字段。多个控制字段允许显式指定数据路径内的并行活动。
水平微程序中的分支也比垂直情况更复杂。每个水平微指令可能至少有一个分支条件和相关的目标地址,微指令格式可能包括一个显式的、无条件的下一个地址字段。编程效果更像是在开发一个有向图(图中有各种循环)的控制信号组。
因此,水平微程序设计对于传统程序员来说不太熟悉,并且更容易出错。然而,水平微程序设计通常提供更好的性能,因为有机会利用数据路径内的并行性,并将微程序分支决策折叠到执行数据路径操作的同一时钟周期内。为水平微代码引擎编程被比作为VLIW处理器所需的编程。
在两级方案中结合垂直和水平微指令的方法称为纳米编程,并在Nanodata QM-1和Motorola 68000中使用。QM-1使用了16K字的微指令控制存储器,每字18位,以及1K字的纳米指令控制存储器,每字360位[Nanodata]。微指令本质上形成了对纳米指令级别例程的调用。水平风格的纳米指令被分为五个72位的字段(见图11)。
SRDAI: "SHIFT RIGHT DOUBLE ARITHMETIC IMMEDIATE"
.... FETCH, KSHC=RIGHT+DOUBLE+ARITHMETIC+RIGHT CTL, SH STATUS ENABLE
KALC=PASS LEFT, ALU STATUS ENABLE
S... A->FAIL, A->FSID, B->KSHR, CLEAR CIN
.S.. A->FAOD, INCF->FSID, A->FSOD
..S. INCF->FSOD
...X GATE ALU, GATE SH, ALU TO COM图11 水平微指令:纳米数据示例
第一个字段(称为K,在图11中用四个点表示)包含一个10位的分支地址(在图11的示例中为FETCH)、各种条件选择子字段和一些控制子字段。剩余的四个字段(称为T1-T4,在图中分别显示在不同的行上)指定要执行的特定微操作。每个T字段包含41个子字段。
在QM-1上执行纳米指令分为四个阶段:K字段持续活跃,而T字段按顺序执行,每个阶段执行一个(注意图11中T1-T4字段的交错S和X字符)。这种方法允许一个360位的纳米指令指定相当于四个144位的纳米指令(即,K字段依次附加每个特定的T字段)。T字段内的顺序子字段提供了重复执行相同的纳米指令,直到某些条件变为真,其他子字段提供了有条件地跳过下一个T字段的功能。
由于以下一些特性,微指令的解释可能比正常指令的解释更复杂:
位导向(bit steering),其中一个字段的值决定了微指令中其他字段的解释;
环境替换(environment substitution),其中用户级寄存器的字段用作当前微指令的计数或操作数说明符;
剩余控制(residual control),其中一个微指令将控制信息存放在一个特殊的设置或配置寄存器中,该寄存器控制后续微指令的动作和解释;
多相位指定(polyphase specification),微指令中的不同字段在不同的时钟相位或时钟周期内活跃(例如,如上所述的Nanodata QM-1);以及,
多阶段指定(multiphase specification),其中ALU活动的持续时间(时钟相位或周期的数量或长度)会显式延长,以适应所需的时间(例如,延长时间以考虑加法期间的进位传播,这也是QM-1的一个特性)。
微程序的顺序执行
微程序的顺序执行由于一个基本规则而变得复杂,即避免任何微指令地址的加法,除非是对计数器的简单增量。因此,在微指令级别,类似于在宏指令级别常见的将偏移量加到程序计数器的分支动作是罕见的。相反,微指令中的地址字段位可能被或入控制存储器地址寄存器,或有条件地替换控制存储器地址寄存器的所有或部分。或者,微指令可能使用多个下一个地址字段,其中指定的条件用于选择使用哪个字段。
子程序调用也可能在微程序级别可用;然而,嵌套级别通常受限于专用控制存储器返回地址堆栈的大小。
为了在解码宏指令时使用,初始映射到特定微程序可以通过以下方法之一完成:
将低阶零附加到宏指令操作码,这意味着微代码例程在控制存储器中被组织为固定偏移段(如Wilkes的原始方案)
将高阶零附加到宏指令操作码,意味着在低内存中使用跳转表
通过特殊解码ROM或PLA进行表查找(如在68000中)
这种初始映射产生微程序中第一个微指令的控制存储器地址,并且微程序顺序执行(或“流程”)继续,直到微程序完成。这在下面的图12(a)中展示。
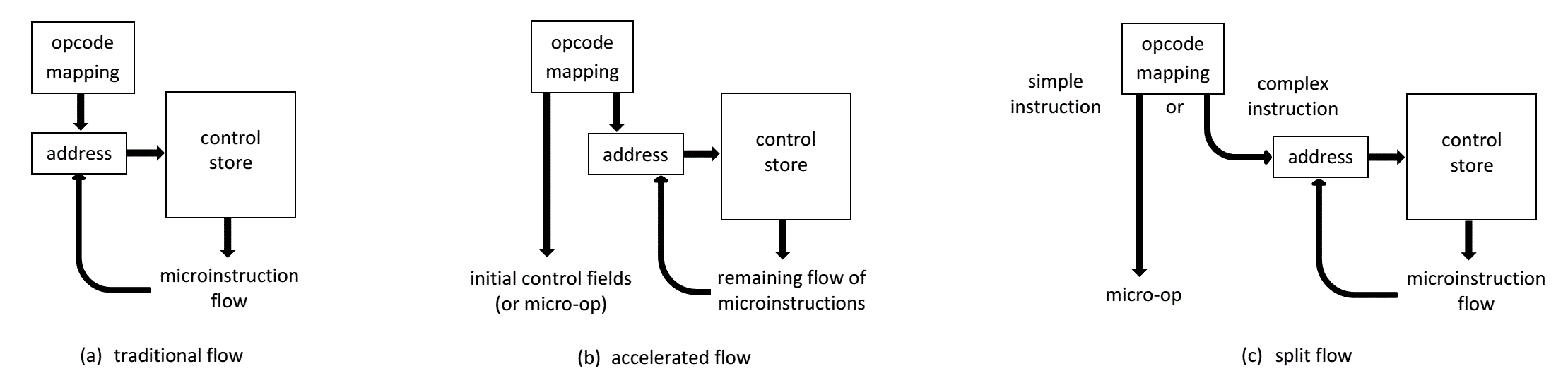
图12 微指令流
由于访问控制存储器通常存在延迟,因此加快控制的一种方法是宏指令操作码映射不仅提供控制存储器入口点,还提供第一个控制字段(或“微操作”),如图12(b)所示。通常包含在第一个微指令中的控制字段因此可以立即生效,并与第二个微指令的控制存储器获取重叠。例如,David Bernstein和Data General microEclipse设计组的其他人在美国专利4,394,736 [Ber83]中描述了这种类型的方法。Beatrice Fu、Avtar Saini和Pat Gelsinger也在Intel i486中描述了一种加速流程;请注意,在他们的术语中,解码器产生的初始微操作称为“硬连线微指令”,从控制存储器中获取的字称为“微代码行”[Fu89]。
此外,由于一些简单的宏指令只需要一个微指令,因此不需要启动控制存储器流程。因此,控制存储器入口点只能为需要多个微操作的复杂宏指令提供,如图12(c)所示。
Intel的俄勒冈设计组在20世纪80年代和90年代使用了多种类似分流的方法:
John Bayliss等人描述了Intel IAPX432的类似分流方法[Bay81]以及美国专利4,415,969。对于简单的宏指令,解码器生成一个进入小型“翻译ROM”的地址,该ROM包含64个“强制微指令”。复杂的宏指令以不同的方式处理,并生成一个进入3.5K控制存储器的起始地址。在简单宏指令的情况下,解码器可以连续生成多达三个“强制微指令”,其中顺序由解码器本身控制,而不是由“强制微指令”控制。
随后的80960设计组使用了一种增强的三部分类似分流方法,其中指令解码器可以根据被解码的宏指令的复杂性生成单个微操作、一系列微操作或控制存储器入口点地址[Mye88]。
P6(Pentium Pro)设计组使用了一种结合加速和分流解码器的方法,可以直接生成多达四个微操作(“uops”)[Col05]。对于一些需要超过四个uops的常用复杂宏指令,此解码器可以在第四个uop之后从控制存储器启动流程。对于其他复杂宏指令,此解码器仅从控制存储器启动流程。还有两个额外的解码器可以与第一个解码器并行操作。每个解码器都更简单,只能生成一个uop以匹配简单的宏指令。
AMD和其他公司设计的几款x86兼容微处理器使用的解码结构与Pentium Pro中使用的类似。参见Bruce Shriver和Bennett Smith的书,详细了解AMD K6-2的内部设计[Shr98],以及Glenn Henry的白皮书,讨论VIA Isaiah的内部设计[Hen08]。
微程序设计工具和语言
大多数微程序设计环境都提供了标准的工具,如微汇编器、链接器、加载器和机器模拟器(可能提供各种形式的调试和跟踪功能)。这些工具必然是依赖于机器的。多年来,人们做出了许多努力来开发高级微程序设计语言(HLMLs),从依赖于机器的方法到独立于机器的方法。前者通常无法移植到其他实现中,或者需要大量的开发成本才能移植;后者通常生成的微代码效率较低。因此,多年来没有出现一种被广泛接受的微程序设计语言。
最早发表的关于为微代码提供更高层次表示的尝试之一是Stuart Tucker对IBM内部用于System/360微代码的流程图语言的描述[Tuc67]。其他早期的工作包括Samir Husson在1970年描述的一种类似Fortran的高级微程序设计语言[Hus70],以及Dick Eckhouse在1971年的博士论文中描述的一种类似PL/I的语言,他称之为MPL。其他值得注意的努力包括1976年David Patterson开发的STRUM,其目标是微代码验证。STRUM是一种类似Algol的块结构语言,提供了循环断言(assert)以及过程前和过程后的断言(assume和conclude)。第一个在多台机器上实现的语言(特别是DEC VAX和HP 300)是由Patterson和他在DEC的同事在1979年完成的,名为YALL,意为“Yet Another Low Level Language”。有关这些努力的更多信息,请参阅Subrata Dasgupta和Scott Davidson的调查论文[Das80,Dav86]。
任何高级微程序设计语言的一个主要设计问题是是否(以及如何)表达并行性和时序约束。一方面,Dasgupta的S*语言(约1978年)使用类似Pascal的语法,但包括两种时序控制结构:cocycle和coend,它们标识在同一时钟周期内活动的并行操作;以及stcycle和stend,它们标识在新时钟周期内一起开始的并行操作(但不一定具有相同的持续时间)。另一方面,Preston Gurd在滑铁卢大学攻读硕士学位时,使用C语言的一个子集作为源代码编写了一个微代码编译器(Micro-C,约1983年)。Gurd发现,在没有显式约束的情况下编写的微程序更容易理解和调试。事实上,调试可以在任何具有C编译器的系统上进行,并使用标准的调试器。此外,为现有的高级语言提供微代码编译器,可以无需进一步编程努力将现有代码转换为微代码。
由于微代码的效率对系统性能至关重要,微程序员及其工具的主要目标之一就是优化。这种优化通常被称为微代码压缩,旨在确保微程序既能在给定大小的控制存储器中容纳,又能以最大性能执行[And80,Hab88]。这种优化可能会重新排序微操作,同时不违反数据和资源依赖关系。一种称为跟踪调度的先进技术由Josh Fisher为横向微程序开发[Rau93]。Fisher的方法是预测一个可能的执行路径(称为“跟踪”),并对该路径进行主要优化。偏离跟踪的路径可能需要补偿代码以保持正确性。向不常执行的路径添加代码在执行时间上的代价相对较小,但这种优化可能会受到控制存储器大小限制的约束。(跟踪调度是Fisher后来与VLIW相关工作的基础。)
微程序设计的总结评价
优点
1. 系统化的控制单元设计
2. 易于实现代码兼容的计算机系列
3. 能够模拟其他计算机系统
4. 能够使用微诊断调试系统
5. 无需重新布线或更换电路板即可进行现场修改
6. 在控制存储器内或不影响封装约束的情况下,增加功能的边际成本较低
7. 使用可写控制存储器的可重构计算
缺点
1. 对于小型系统来说不经济,因为控制存储器和微指令序列逻辑的固定成本相对较高
2. 多了一层解释,带来了相应的开销
3. 指令周期时间受限于控制存储器的访问时间
4. 支持工具有限
附录部分:MIT旋风计算机控制设计
旋风计算机是麻省理工学院开发的一款早期实时计算机。其开发始于1945年末,并于1950年投入运行。旋风计算机在控制设计方面采用了非常系统化的方法,使用三个二极管矩阵来实现控制信号:操作矩阵、操作时序矩阵和程序时序矩阵。(参见R.R. Everett和F.E. Swain的报告《Whirlwind I计算机框图》,报告编号R-127,麻省理工学院伺服机构实验室,1947年,图49、54、55和58。)这些二极管矩阵被称为“控制存储器”。其主要设计师之一罗伯特·埃弗雷特(Robert Everett)将旋风计算机描述为“具有非常灵活的控制,以允许添加和修改指令。... 通过焊接二极管来改变现有指令或添加新指令。”[R.R. Everett,《旋风计算机》,收录于N. Metropolis、J. Howlett和G.C. Rota(编)的《二十世纪计算史》,学术出版社,1980年,第365-384页。]
计算机历史博物馆的一张照片显示,诺曼·泰勒(在面板后面)、罗伯特·埃弗雷特和格斯·奥布莱恩正在检查其中一个控制矩阵。

在1947年的报告中以及1951年的会议演示中(例如,参见Everett在Bell和Newell中重印的论文),使用了以下简化图表来传达旋风计算机生成控制信号的一般方法。顶部解码器根据5位操作码选择32条指令线中的一条。一条指令线可以与任意8个时序脉冲中的任何一个组合,以生成一个控制脉冲。
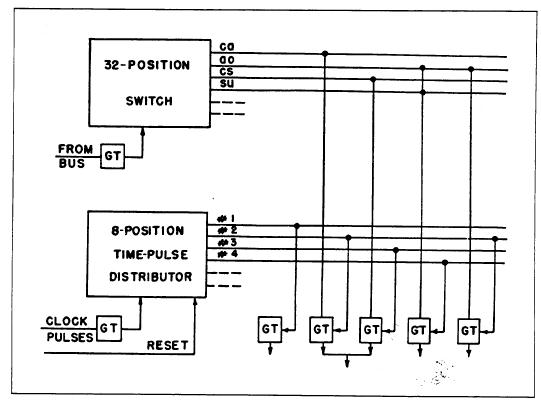
Saul Rosen在他的1969年论文《电子计算机:历史调查》(发表在ACM计算调查中)中报告:
旋风项目的主要贡献之一是一组详细且注释良好的计算机逻辑图。尽管没有正式出版,但它们在私人圈子里相当广泛地流传,并帮助教育了许多计算机领域的早期工作者(包括作者本人[即Rosen本人])。
Wilkes在1950年9月访问了旋风计算机。参见他的书《计算机先驱回忆录》,麻省理工学院出版社,1985年,第176页及以后。第177-178页的摘录:
正是在我刚刚描述的这次旅行中,以及随后的几个月里,我对微程序设计的想法逐渐成型。我们曾试图使EDSAC控制部分的设计尽可能系统化,但其中包含大量现在称为随机逻辑的内容。我觉得一定有一种方法可以用更系统的东西来取代它,也许可以沿着用于解码功能数字并在随后重新编码以驱动计算机中各种门的二极管配置的思路。我在RMS纽芬兰号横渡大西洋的航行中,有机会对这个主题进行一些安静的思考,后来当我看到旋风计算机时,我发现它的确有一个基于二极管矩阵的集中控制。然而,它只能产生一个固定的8脉冲序列——每个指令的序列不同,但对于特定的指令来说仍然是固定的。我想,直到我回到剑桥,我才意识到解决方案是将控制单元变成一个微型计算机,通过添加第二个矩阵来确定微级别的控制流,并提供条件微指令。在冬天的某个时候,这些想法逐渐成型,我给我的同事们做了一次即兴讲座。随后,我将它们写下来,并在1951年7月在曼彻斯特大学举行的一次会议上发表,以庆祝Ferranti Mark I计算机的完成。
参见M.V. Wilkes,《微程序设计兴趣的增长:文献调查》,ACM计算调查,第1卷,第3期,1969年,第139-145页,他在其中也描述了旋风计算机的控制存储器,以及他在M.V. Wilkes,《控制单元的设计——阅读Babbage笔记本的反思》,IEEE计算机历史年鉴,第3卷,第2期,1981年,第116-120页中对Charles Babbage、旋风计算机和微程序设计的评论。
附录部分:其他早期硬连线控制设计的例子
EDVAC
T. Kite Sharpless在1946年夏季作为宾夕法尼亚大学摩尔电气工程学院摩尔学校讲座的一部分,就早期的EDVAC串行设计进行了两次讲座。讲座附带的图表描绘了使用10 x 25开关矩阵作为指令解码器的一般概念,但没有给出详细的开关连接。解码器接受一个五位操作码,并分别生成用于加法、减法和乘法指令(即“指令”)的“A”、“S”和“M”信号。图中还描绘了由解码器生成的其他五个信号。
ALU(即“高速二进制计算机”)的单独图表描绘了使用,但未生成更具体的A、S和M控制信号,例如“A1P2”表示加法指令,次周期1,脉冲2,以及“M1P2-7”表示乘法指令,次周期1,脉冲2到7。
参见讲座47,M. Campbell-Kelly和M.R. Williams(编辑),《摩尔学校讲座》,麻省理工学院出版社,1985年,第546-560页(附有两张折叠图表)。另见这张早期手绘的EDVAC图表。
MIT旋风项目的David Brown和Robert Everett被邀请参加讲座系列,Jay Forrester也参加了其中的一些讲座。Maurice Wilkes是另一位受邀者,但只能参加最后两周的讲座。
曼彻斯特大学SSEM
弗雷德里克·威廉姆斯、汤姆·基尔本和杰夫·图特尔于1948年在英国曼彻斯特大学建造了一台小型实验计算机,用于测试威廉姆斯管存储器设计。在F.C.威廉姆斯、T.基尔本和G.C.图特尔的论文《通用高速数字计算机:小型实验机器》(Proceedings of the Institution of Electrical Engineers (IEE), v. 98, part II, n. 61, February 1951, pp. 13-28)的图9中,给出了小型实验机器(昵称为“Baby”)的完整框图,包括控制信号。控制信号被标记为六个信号“0/13”、“1/13”、“0/14”、“1/14”、“0/15”和“1/15”,它们表示操作码(即位位置13-15中的“功能编号”)中的各个位是0还是1。没有开关矩阵,而是在数据路径的不同点上组合这些六个信号的子集来执行控制功能。
EDSAC
彼得·罗宾逊和凯伦·琼斯的《EDSAC 99纪念册》(University of Cambridge Computer Laboratory, April 1999)中在线提供了威尔克斯和雷纳克的1949年会议论文《EDSAC》的重印本。重印本中的框图出现在小册子的第61和62页,分别显示了指令获取和加法操作执行的主动控制信号。
萨布拉塔·达斯古普塔的《发明与设计中的创造力:技术原创性的计算与认知探索》(Cambridge University Press, 1994)一书中,对威尔克斯发明微程序的案例研究是一个重要部分。第三章讨论了EDSAC和EDSAC 2。
埃克特和莫奇利BINAC
J.普雷斯珀·埃克特和约翰·莫奇利于1946年离开宾夕法尼亚大学的摩尔学院,成立了埃克特-莫奇利计算机公司。EMCC在1948年接受了一台大型UNIVAC机器的订单,并在1949年完成了一台较小的BINAC机器的订单。BINAC中的控制信号是通过使用两个称为“功能表”的二极管矩阵生成的。这些矩阵在A.A.奥尔巴赫、J.P.埃克特、R.F.肖、J.R.韦纳和L.D.威尔逊的论文《BINAC》(Proceedings of the IRE, v. 40, n. 1, January 1952, pp. 12-29)中有详细描述。
IAS
《电子计算仪器物理实现的第三次临时进展报告》指出,IAS机器的“控制器官”工作在1948年1月“刚刚开始密集进行”(第111页)。事实上,到1951年第六次临时报告时,控制电路仍被描述为“零碎的”。杰拉尔德·埃斯特林在《高级研究学院电子计算机的描述》(Proceedings of the 1952 ACM National Meeting, Toronto, 1952, pp. 95-109)中讨论了异步定时链,并详细介绍了加法指令的操作。IAS设计的细节也在1954年的《电子计算仪器物理实现的最终进展报告》中有所展示。
IBM 701
IBM 701的控制信号逻辑出现在美国专利2,974,866的各种图纸中,J.A. Haddad、R.K. Richards、N. Rochester和H.D. Ross, Jr.,“电子数据处理机”,1954年3月30日申请,1961年3月14日颁发。
IBM的Frank Beckman、Fred Brooks和William Lawless在《计算机算术和控制单元逻辑组织的发展》,《IRE会议录》,第94卷,第1期,1961年1月,第53-66页中讨论了同步和异步控制:
经典的同步技术用于操作阶段的排序,使用闩锁环或计数器-解码器从振荡器或其他时钟沿适当的门控线分发一系列定时脉冲。这些技术仍然被广泛使用。
同样古老且今天仍然广泛使用的是异步技术,其中每个操作阶段的完成都会产生一个脉冲,启动下一个阶段。在广泛使用的异步技术变体中,每个操作都是独立定时的,并且每个操作都会信号启动下一个操作。
下表比较了20世纪40年代末和50年代的几种设计。
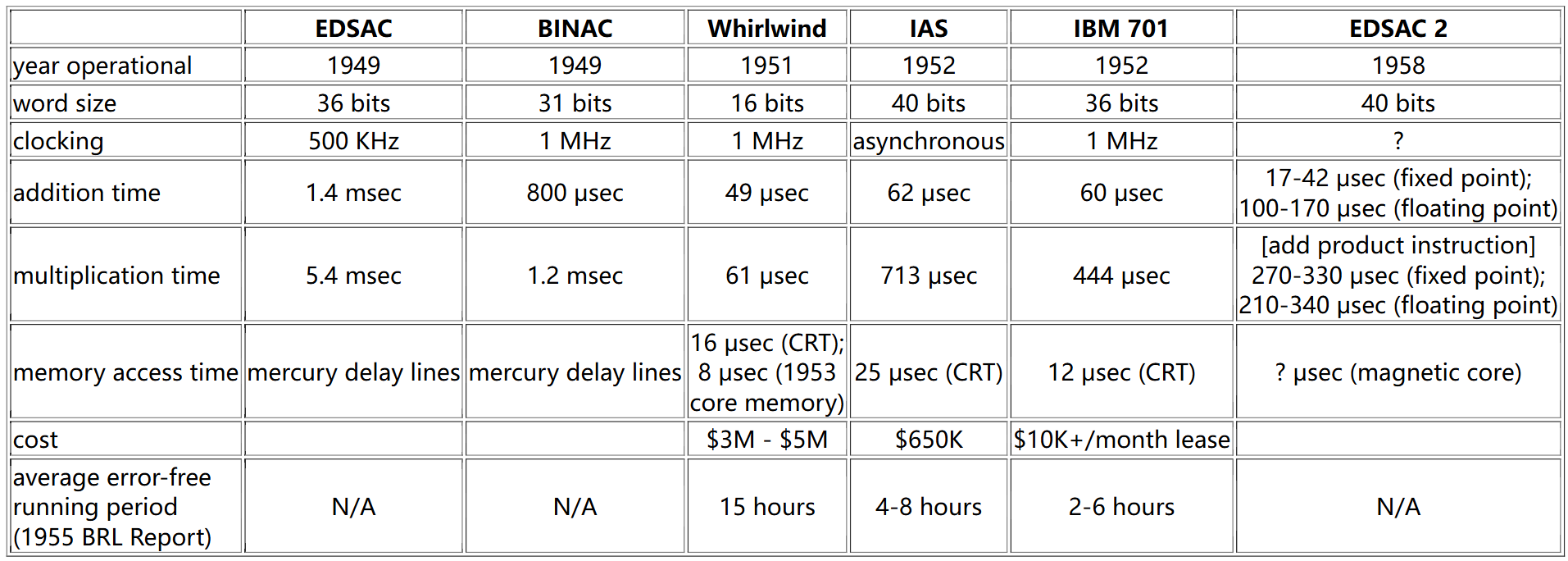
上表的数据来源:
M.H. Weik , "A Survey of Domestic Electronic Digital Computing Systems," U.S. Army Ballistic Research Laboratories, Report No. 971, December 1955.
S.H. Lavington, Early British Computers, Digital Press, 1980;
K.C. Redmond and T.M. Smith, Project Whirlwind: The History of a Pioneer Computer, Digital Press, 1980.
H.D. Huskey, "Hardware Components and Computer Design," in R. Rojas and U. Hashagen (eds.), The First Computers: History and Architectures, MIT Press, 2000.
参考文献
[Anc86] F. Anceau. The Architecture of Microprocessors. Workingham, England: Addison-Wesley, 1986.
[And80] M. Andrews. Principles of Firmware Engineering in Microprogram Control. Potomac, MD: Computer Science Press, 1980.
[Agr76] A.K. Agrawala and T.G. Rauscher. Foundations of Microprogramming. New York: Academic Press, 1976.
[Atk74] T. Atkinson, "Architecture of Series 60/Level 64," Honeywell Computer Journal, v. 8, n. 2, 1974, pp. 94-106.
[Bad92] R. Badeau, et al., "A 100 Mhz Macropipelined CISC CMOS Microprocessor," IEEE Journal of Solid-State Circuits, v. 27, n. 11, 1992, pp. 1585-1598.
See also Bob Supnik's archive of the NVAX microcode listings.
[Bar92] R.J. Baron and L. Higbie. Computer Architecture: Case Studies. Reading, MA: Addison-Wesley, 1992.
[Bay81] J.A. Bayliss, et al., "The Instruction Decoding Unit for the VLSI 432 General Data Processor," IEEE Journal of Solid-State Circuits, v. 16, n. 5, October 1981, pp. 531-537.
See also US Patent 4,415,969, "Macroinstruction Translator Unit for Use in a Microprocessor," 1983.
A similar split-flow approach was used for the CDC Cyber 180. See US Patent 4,390,946, "Lookahead Addressing in a Pipeline Computer Control Store with Separate Memory Segments for Single and Multiple Microcode Instruction Sequences," 1983.
[Bel78] C.G. Bell, J.C. Mudge, and J.E. McNamara. Computer Engineering: A DEC View of Hardware Systems Design. Bedford, MA: Digital Press, 1978.
[Ber83] D.H. Bernstein, et al., "Data Processing System Utilizing a Unique Two-Level Microcoding Technique for Forming Microinstructions," US Patent 4,394,736, assigned to Data General, July 19, 1983.
Similar accelerated flow approaches are described by R.L. Harris and R.W. Horst of Tandem in US Patent 4,574,344, "Entry Control Store for Enhanced CPU Pipeline Performance," 1986, and by J.C. Rhodes, et al., of IBM in US Patent 4,685,080, "Microword Generation Mechanism Utilizing Separate Programmable Logic Arrays for First and Second Microwords," 1987.
An earlier approach using a separate control store for first microinstructions that is narrower than the main control store is described in US Patent 3,800,293, "Microprogram Control Subsystem," 1974.
[Bha91] D. Bhandarkar and D.W. Clark, "Performance from Architecture: Comparing a RISC and a CISC with Similar Hardware Organization," Proceedings of the 4th International Conference on Architectural Support for Programming Languages and Operating Systems [ASPLOS IV], 1991, pp. 310-319.
Note that the VAX 8600 in 1984 was pipelined at the macroinstruction level, but the VAX 8800 in 1986 was pipelined at the microinstruction level. See:
J. DeRosa, R. Glackemeyer, and T. Knight, "Design and Implementation of the VAX 8600 Pipeline", IEEE Computer, v. 18, no. 5, 1985, pp. 38-48.
D.W. Clark, "Pipelining and Performance in the VAX 8800 Processor," Proceedings of the Second International Conference on Architectual Support for Programming Languages and Operating Systems [ASPLOS II], 1987, pp. 173-177.
[Bla08] D. Black-Schaffer, et al., "Hierarchical Instruction Register Organization," Computer Architecture Letters, v. 7, n. 2, 2008. Available on-line as http://cva.stanford.edu/projects/elm/pubs/cal_Jul_2008.pdf.
[Burroughs] B1700 manuals. Available on-line at http://www.textfiles.com/bitsavers/pdf/burroughs/B1700/
[Che08] A.C. Cheng, "Amplifying Embedded System Efficiency via Automatic Instruction Fusion on a Post-Manufacturing Reconfigurable Architecture," Proceedings of the International Symposium on Quality Electronic Design [ISQED], 2008, pp. 744-749.
See also, among other papers by Cheng and colleagues on Framework-based Instruction-set Tuning Synthesis (FITS), A.C. Cheng and G.S. Tyson, "High-Quality ISA Synthesis for Low-Power Cache Designs in Embedded Microprocessors," IBM Journal of Research and Development, v. 50, n. 2/3, 2006, pp. 299-309. Available on-line as http://www.research.ibm.com/journal/rd/502/cheng.html.
[Cir95] J. Circello, "Coldfire: A Hot Processor Architecture," Byte, v. 20, no. 5, 1995, pp. 173-174.
[Col05] R.P. Colwell, et al., "Intel's P6 Microarchitecture," Chapter 6 in J.P. Shen and M.H. Lipasti, Modern Processor Design. New York: McGraw Hill, 2005.
[Das80] S. Dasgupta, "Some Aspects of High Level Microprogramming," ACM Computing Surveys, v. 12, n. 3, 1980, pp. 295-323.
[Dav86] S. Davidson, "Progress in High-Level Microprogramming," IEEE Software, v. 3, n. 4, 1986, pp. 18-26.
[Dor88] R.W. Doran, "Amdahl Multiple-Domain Architecture," IEEE Computer, v. 21, no. 10, 1988, pp. 20-28.
See also US Patent 4,967,342, "Data Processing System having Plurality of Processors and Channels Controlled by Plurality of System Control Programs through Interrupt Routing," 1990.
[Fu89] B. Fu, A. Saini, and P. Gelsinger, "Performance and Microarchitecture of the i486 Processor," Proceedings of the IEEE International Conference on Computer Design [ICCD], 1989, pp. 182-187.
See also US Patent 5,293,592, "Decoder for Pipelined System Having Portion Indicating Type of Address Generation and Other Portion Controlling Address Generation within Pipeline," 1994.
[Fu18] X. Fu, et al., "A Microarchitecture for a Superconducting Quantum Processor," IEEE Micro, v. 38, n. 3, 2018, pp. 40-47.
[Gon00] R.E. Gonzalez, "Xtensa: A Configurable and Extensible Processor," IEEE Micro, v. 20, n. 2, 2000, pp. 60-70.
[Hab88] S. Habib (ed.), Microprogramming and Firmware Engineering Methods. New York: van Nostrand, 1988.
[Ham90] V.C. Hamacher, Z.G. Vranesic, and S.G. Zaky. Computer Organization (3rd ed.). New York: McGraw-Hill, 1990.
[Hel05] L.C. Heller and M.S. Farrell, "Millicode in an IBM zSeries Processor," IBM Journal of Research and Development, v. 48, n. 3/4, 2005, pp. 425-434. Available on-line as http://www.research.ibm.com/journal/rd/483/heller.html.
See also J. Maergner and H.R. Schwermer, "I370 - A New Dimension of Microprogramming," ACM SIGMICRO Newsletter, v. 19. n. 3, 1988, pp. 24-31.
[Hen08] G.G. Henry, "The VIA Isaiah Architecture," Centaur Technology, 2008.
[Hop00] W. Hopmann, "The G1 and the Göttingen Family of Digital Computers," in R. Rojas and U. Hashagen, The First Computers - History and Architectures. Cambridge, MA: MIT Press, 2000, pp. 295-313.
[Hus70] S.H. Husson, Microprogramming: Principles and Practice. Englewood Cliffs, NJ: Prentice Hall, 1970.
[Int21] Intel, "XuCode: An Innovative Technology for Implementing Complex Instruction Flows," May 6, 2021. Available online at https://www.intel.com/content/www/us/en/developer/articles/technical/software-security-guidance/secure-coding/xucode-implementing-complex-instruction-flows.html
[Joh71] A.M. Johnson, "The Microdiagnostics for the IBM System 360 Model 30," IEEE Transactions on Computers. v. C-20, n. 7, 1971, pp. 798-803.
[Lar82] J.R. Larus, "A Comparison of Microcode, Assembly Code, and High-Level Languages on the VAX-11 and RISC I," ACM Computer Architecture News, v. 10, n. 5, 1982, pp. 10-15.
[Lav78] S.H. Lavington, "The Manchester Mark I and Atlas: A Historical Perspective," Communications of the ACM, v. 21, n. 1, 1978, pp. 4-12.
See also http://www.chilton-computing.org.uk/acl/technology/atlas/p007.htm.
[McC65] M.A. McCormack, T.T. Schansman, and K.K. Womack, "1401 Compatibility Feature on the IBM System/360 Model 30," Communications of the ACM, v. 8, n. 12, 1965, pp. 773-776.
[McK79] J. McKevitt and J. Bayliss, "New Options from Big Chips," IEEE Spectrum, v. 16, n. 3, 1979, pp. 28-34.
Regarding the microcode on the Intel 8086, see also
US Patent 4,363,091, "Extended Address, Single and Multiple Bit Microprocessor," 1982.
Andrew Jenner, "8086 Microcode Disassembled," Reenigne blog, September 2020 (updated January 2023).
multiple posts at Ken Shirriff's blog on the Intel 8086 during 2022 and 2023, including:
Reverse-engineering the ModR/M addressing microcode in the Intel 8086 processor
Reverse-engineering the register codes for the 8086 processor's microcode
The microcode and hardware in the 8086 processor that perform string operations
Reverse-engineering the division microcode in the Intel 8086 processor
[Mic80] J. Mick and J. Brick. Bit-Slice Microprocessor Design. New York: McGraw-Hill, 1980.
[Microdata] Microdata 1600 manuals. Available on-line at http://www.textfiles.com/bitsavers/pdf/microdata/
[Mye78] G.J. Myers. Advances in Computer Architecture. 2nd ed. New York: Wiley, 1978.
[Mye88] G.J. Myers and D.L. Budde. The 80960 Microprocessor Architecture. New York: Wiley, 1988.
See also US Patent 4,891,753, "Register Scoreboarding on a Microprocessor Chip," 1990.
[Nanodata] Nanodata QM-1 manuals. Available on-line at http://www.textfiles.com/bitsavers/pdf/nanodata/
See also US Patent 3,766,532, "Data Processing System Having Two Levels of Program Control," 1973.
[Opl67] A. Opler, "Fourth-Generation Software," Datamation, v. 13, n. 1, 1967, pp. 22-24.
[Pad81] A. Padegs, "System/360 and Beyond," IBM Journal of Research and Development, v. 25, n. 5, 1981, pp. 377-390. Available on-line as http://www.research.ibm.com/journal/rd/255/ibmrd2505D.pdf.
[Pat98] D.A. Patterson and J.L. Hennessy. Computer Organization and Design: The Hardware / Software Interface (2nd ed.). San Mateo, CA: Morgan Kaufmann, 1998.
[Phi79] M. Phister, Jr. Data Processing Technology and Economics (2nd ed.). Bedford, MA: Digital Press, 1979.
[Pug91] E.W. Pugh, L.R. Johnson, and J.H. Palmer. IBM's 360 and Early 370 Systems. Cambridge, MA: MIT Press, 1991.
[Rau93] B.R. Rau and J. Fisher, "Instruction-Level Parallel Processing: History, Overview, and Perspective," Journal of Supercomputing, v. 7, 1993, pp. 9-50.
[Ren56] W. Renwick, "EDSAC II," Proceedings of the IEE, v. 103B, n. 2, April 1956, pp. 277-278.
[Res05] M. Reshadi, B. Gorjiara, and D. Gajski, "Utilizing Horizontal and Vertical Parallelism Using a No-Instruction-Set Compiler and Custom Datapaths", Proceedings of the International Conference on Computer Design [ICCD], 2005, pp. 69-76.
See also http://www.ics.uci.edu/~nisc/.
[Rog12] B. Rogers, "The What and Why of zEnterprise Millicode," IBM Systems Magazine, Mainframe Edition, Sept.-Oct. 2012, pp. 32-34.
[Sal76] A.B. Salisbury. Microprogrammable Computer Architectures. New York: Elsevier, 1976.
[Shi79] M. Shima, "Demystifying Microprocessor Design," IEEE Spectrum, v. 16, n. 7, 1979, pp. 22-30.
[Shr98] B. Shriver and B. Smith. The Anatomy of a High-Performance Microprocessor: A Systems Perspective. Los Alamitos, CA: IEEE Computer Society Press, 1998.
[Ste81] L. Stevens, "The Evolution of Magnetic Storage," IBM Journal of Research and Development, v. 25, n. 5, 1981, pp. 663-675.
[Str78] S. Stritter and N. Tredennick, "Microprogrammed Implementation of a Single Chip Microprocessor," Proceedings of the 11th Annual Microprogramming Workshop [MICRO-11], 1978, pp. 8-16.
See also US Patent 4,307,445, "Microprogrammed Control Apparatus having a Two-Level Control Store for Data Processor," 1981, and US Patent 4,325,121, "Two-Level Control Store for Microprogrammed Data Processor," 1982.
[Tar19] M. Taram, A. Venkat, and D. Tullsen, "Context-Sensitive Decoding: On-Demand Microcode Customization for Security and Energy Management," IEEE Micro, v. 39, n. 3, 2019, pp. 75-83.
See also US Patent 3,325,788, "Extrinsically Variable Microprogram Controls," 1967.
[Tre88] N. Tredennick, "Experiences in Commercial VLSI Microprocessor Design," Microprocessors and Microsystems, v. 12, n. 8, 1988, pp. 419-432.
[Tre82] N. Tredennick, "The Cultures of Microprogramming," Proceedings of the 15th Annual Microprogramming Workshop [MICRO-15], 1982, pp. 79-83.
[Tuc65] S.G. Tucker, "Emulation of Large Systems," Communications of the ACM, v. 8, n. 12, 1965, pp. 753-761.
[Tuc67] S.G. Tucker, "Microprogram Control for System/360," IBM Systems Journal, v. 6, n. 4, 1967, pp. 222-241. Available on-line as http://www.research.ibm.com/journal/sj/064/ibmsj0604B.pdf.
See also Ken Shirriff, "Simulating the IBM 360/50 Mainframe from its Microcode," blog post, 2022.
[Tuc99] S.G. Tucker, personal communication, February 1999.
[Web97] C.F. Webb and J.S. Liptay, "A High-Frequency Custom CMOS S/390 Microprocessor," IBM Journal of Research and Development, v. 41, n. 4/5, 1997, pp. 463-473. Available on-line as http://www.research.ibm.com/journal/rd/414/webb.html.
[Web08] C.F. Webb, "IBM z10: The Next-Generation Mainframe Microprocessor," IEEE Micro, v. 28, n. 3, 2008, pp. 19-29.
descriptions of subsequent IBM z196 design (July 2010):
"The z196 offers 984 instructions, of which 762 are implemented entirely in hardware." [p. 57, IBM zEnterprise System Technical Introduction, August 2010 (draft Redbook pdf)]
"There are 246 complex instructions executed by millicode and another 211 complex instructions cracked into multiple RISC like operations." [p. 72, IBM zEnterprise System Technical Guide, August 2010 (draft Redbook pdf)]
[note: 762 + 246 = 1008]
[Whe92] D.J. Wheeler, "The EDSAC Programming Systems," IEEE Annals of the History of Computing, v. 14, n. 4, 1992, pp. 34-40.
[Wil51] M.V. Wilkes, "The Best Way to Design an Automated Calculating Machine," Manchester University Computer Inaugural Conf., 1951, pp. 16-18.
- Reprinted in: MV Wilkes, "The Genesis of Microprogramming," IEEE Annals of the History of Computing, v. 8, n. 3, 1986, pp. 116-126.
[Wil53] M.V. Wilkes and J.B. Stringer, "Microprogramming and the Design of the Control Circuits in an Electronic Digital Computer," Proceedings of the Cambridge Philosophical Society, v. 49, 1953, pp. 230-238.
- Reprinted as chapter 11 in: D.P. Siewiorek, C.G. Bell, and A. Newell. Computer Structures: Principles and Examples. New York: McGraw-Hill, 1982.
- Also reprinted in: M.V. Wilkes, "The Genesis of Microprogramming," IEEE Annals of the History of Computing, v. 8, n. 3, 1986, pp. 116-126.
[Wil58] M.V. Wilkes, W. Renwick, and D.J. Wheeler, "The Design of the Control Unit of an Electronic Digital Computer," Proceedings of the IEE, v. 105B, n. 20, 1958, pp. 121-128.
[Wil85] M.V. Wilkes, Memoirs of a Computer Pioneer. Cambridge, MA: MIT Press, 1985.
[Wil92] M.V. Wilkes, "EDSAC 2," IEEE Annals of the History of Computing, v. 14, n. 4, 1992, pp. 49-56.